Abstract
We apply dataset distillation to pre-trained self-supervised vision models by directly optimizing just a single image per class to train an optimal linear classifier on top of these models. To accomplish this, we introduce Linear Gradient Matching (described below) to directly optimize our distilled images from scratch. Our method out-performs all real-image baselines and further excels on fine-grained visual classification datasets. Furthermore, the distilled images offer interesting interpretability results by partially revealing what and how these models actually see, particularly when trained on data with spurious correlations. Please see our paper for full results and our Image Gallery to browse all distilled images.
Method
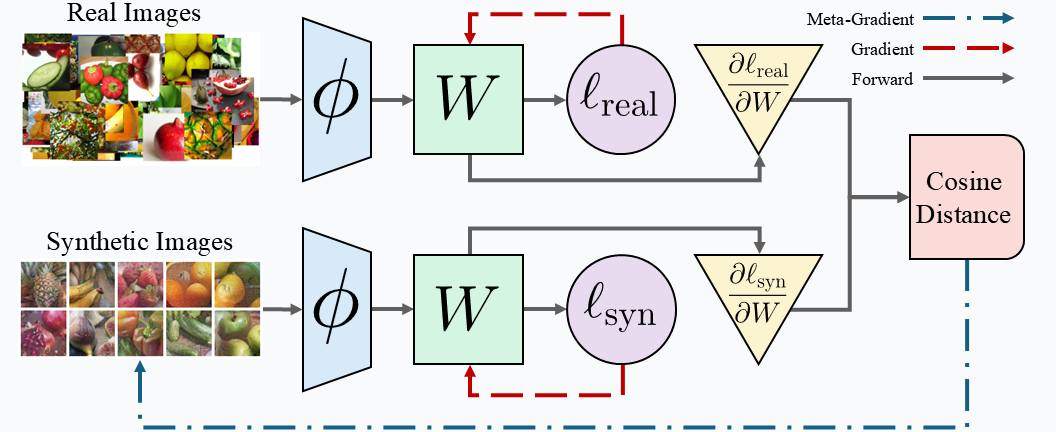
We optimize our synthetic images such that they induce similar gradients as real images when training a linear classifier (W) on top of a pre-trained model (ϕ). To do this, we perform a bi-level optimization by finding the cosine distance between the real and synthetic gradients and back-propagating through the initial gradient calculation all the way to the synthetic images themselves.
ImageNet-1k (1 Image/Class)
After distillation, we evaluate by training new linear classifiers from scratch on the synthetic data (or real-image baselines). Our distilled images consistently out-perform all baselines across all models and datasets. Please see our paper for many more results, including cross-model performance and evaluation on more datasets, including those with fine-grained classes and spurious correlations.
Qualitative Results
Pictured below are a selection of ImageNet-100 classes distilled using different backbone models. The distilled images look quite different for each backbone due to each model's unique set of biases. Please see our Image Gallery to browse all distilled images.

CLIP

DINO-v2

EVA-02

MoCo-v3
Other Datasets Preview
Here we show a preview of our other datasets distilled with CLIP. Our method excels at fine-grained visual classification datasets such as these since the learned images can capture far more discriminative detail than any one real image. Please see our Image Gallery to browse the full distilled datasets from all models (CLIP, DINO-v2, EVA-02, and MoCo-v3).

Flowers-102

Caltech-UCSD Birds

Food-101

Stanford Dogs
BibTeX
@inproceedings{cazenavette2025lgm,
title={Dataset Distillation for Pre-Trained Self-Supervised Vision Models},
author={George Cazenavette and Antonio Torralba and Vincent Sitzmann},
journal={{NeurIPS}},
year={2025},
}